Python tools for Windows forensics: Mozilla Firefox browsing history

After extracting data from Google Chrome last month, next on our journey into the eye-opening world of Windows forensics it’s time to retrieve the user’s Firefox history to see which websites they’ve been visiting in Mozilla’s browser.
What is the Firefox history and how does it help our investigation?
I’m sure everyone’s familiar with what an internet browser history is and what it shows – and if you’re not then maybe try reading my guide to extracting a user’s Google Chrome history.
Firefox’s history data can be found in a file called places.sqlite, which is stored in the user’s directory under \AppData\Roaming\Mozilla\Firefox\Profiles\ in the folder corresponding to the user’s Firefox profile. As the filename extension suggests, this file is in the SQLite format, meaning we’ll need to use a special Python library and SQL-style commands to parse it.
Setting things up
Like the other MCAS Windows Forensic Gatherer modules, the Firefox history function relies on information entered by the analyst at the start of the main script, so we’ll need to pull this in.
import sqlite3
global windows_drive
global username
firefox_directory = windows_drive + ":\Users\\" + username + "\AppData\Roaming\Mozilla\Firefox\Profiles\\"
print "Accessing Firefox browsing history."First we import sqlite3, which is a Python library that will allow us to manipulate the SQLite database. Then we import the global variables windows_drive and username, which contain the Windows drive letter and the subject’s username respectively. These are then used to generate the path to the Firefox Profiles folder and assign it to the firefox_directory variable.
Iterating through the user’s Firefox profiles
Within the Profiles directory there may be several different profile directories. So first we’ll identify them and iterate through them so we can extract the history data from each.
firefox_profiles = os.listdir(firefox_directory)
for profile in firefox_profiles:
database_file = windows_drive + ":\Users\\" + username + "\AppData\Roaming\Mozilla\Firefox\Profiles\\" + profile + "\places.sqlite"The os library’s listdir function generates a list of all folders within the Profiles directory and assigns it to the firefox_profiles variable. Then for each of these profiles we generate the full path of the places.sqlite file and assign it to database_file.
Fetching URLs and visit data
There are several tables within the places.sqlite database – including one containing visited URLs and one containing visit metadata – so we need to extract the data from each separately and match them to each other. We’ll start by grabbing the list of visited URLs.
db = sqlite3.connect(database_file)
cursor = db.cursor()
cursor.execute("SELECT * from moz_places")
url_data = (cursor.fetchall())We use sqlite3 to access the database file and select every record from the table moz_places. This data is assigned to the url_data variable. Next we need the visit metadata.
db = sqlite3.connect(database_file)
cursor = db.cursor()
cursor.execute("SELECT * from moz_historyvisits")
browsing_data = (cursor.fetchall())The method is much the same. We select every record from the moz_historyvisits table and store them in the browsing_data variable. Now we need to match the two together.
Combining the browsing data
If we take a look at the data in browsing_data and url_data, we can see they share a unique identifier. This is the third value in each browsing_data record and the first in each url_data record.
for record in browsing_data:
url_reference = record[2]
for saved_url in url_data:
if saved_url[0] == url_reference:
visit_url = saved_url[1]We iterate through each of the browsing_data records and extract the third value (record[2]). Then we iterate through each of the records in url_data to look for a matching identifier in saved_url[0]. If the two values match then we save the actual URL (saved_url[1]) to visit_url.
Now that we have a matching URL and metadata record, we need to extract the relevant timestamp and convert it to the same format as the rest of our CSV timeline.
visit_time = str(datetime.datetime(1970,1,1) + datetime.timedelta(microseconds=record[3]))
visit_time = visit_time[:-7]First we grab the timestamp from record[3] and convert the time delta to the correct format with datetime. It is converted to a string with str, stored in the visit_time variable, and trimmed to the right length so it will match the CSV timeline entries created by our other forensic modules.
Writing the results to the CSV timeline
Our final task is to assemble each Firefox history record into a line that matches our timeline and append it to the output CSV file with the rest of the gathered data.
visit_line = visit_time + "," + "Website visited (Firefox)" + "," + "," + visit_url + "," + username + "," + "," + "," + visit_time + "," + "," + "Firefox history" + "," + profile + "\places.sqlite" + "\n"
timeline_csv.write(visit_line)
print "Firefox browsing history gathered."
print ""We combine the visit time, URL, username, and – importantly – the name of the Firefox profile the data was retrieved from into a line and add it to the CSV file. Then, once all the data has been added, we write a confirmation message to the screen to let the analyst know the module finished successfully.
The output
Like every month, we’ll filter our events to see what’s been added to the timeline – and as you can see below, we now have a list of websites visited with Mozilla Firefox.
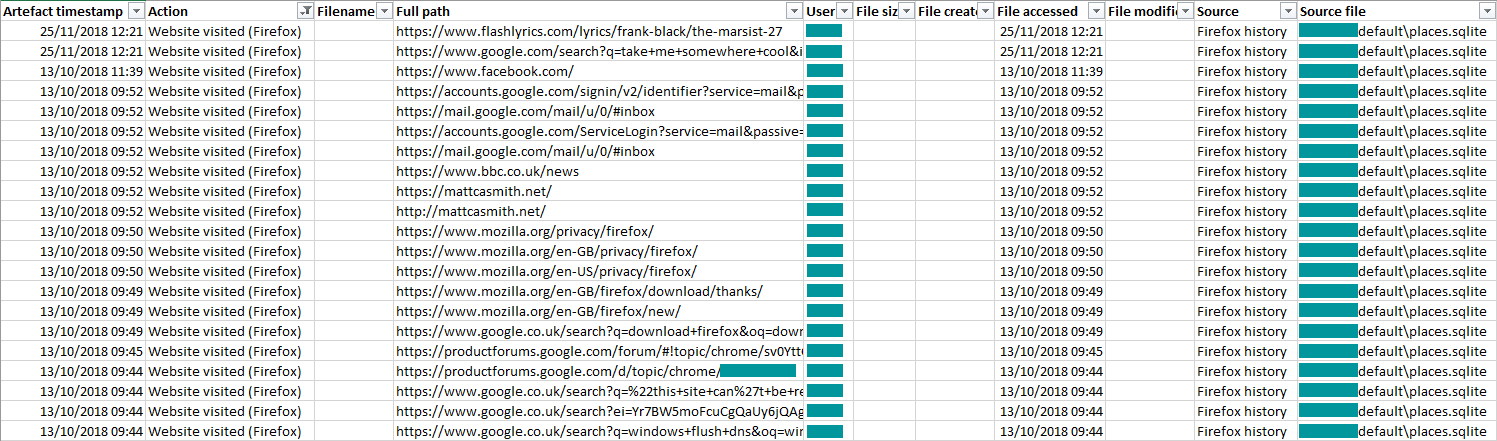
These Firefox visits now join Prefetch data, deleted files, logons and logoffs, recently accessed Microsoft Office files, and Google Chrome website visits in our forensic timeline.
Next month, we’ll take a look at how to record active network connections on the system. Until then, head to the MCAS Windows Forensic Gatherer page if you missed any other posts in the series.
Photo © Jean-Marc Albert (CC BY-SA 2.0). Cropped.