Agentic AI could be the catalyst for safer autonomy
Granting artificial intelligence (AI) access to tools capable of taking real-world actions might fill you with a sense of dread - arguably it should. Given the number of inaccuracies most AI models confidently assert as truth, it feels prudent to maintain a watchful human eye over AI-powered workflows.
But agentic AI presents a new proposition. By connecting agents specialised in certain tasks - and enforcing strict controls on accepted input, output, and escalation points - it could be possible to let AI operate autonomously while maintaining confidence that it will call for help when needed.

Why it’s hard to trust autonomous AI
Since the original ChatGPT exploded onto the scene in late 2022, AI has morphed from a fun toy into a useful sidekick. However, those touting it as a revolutionary technology that will put us all out of jobs by running the world autonomously still tend to fall into two categories: they’re either leaders of companies that build or heavily utilise AI models, or they have personal brands that rely on cultivating an image as visionaries and oracles.
Practically, besides being fun to play with, large language models (LLMs) like ChatGPT are now a useful way to discover information. A search engine like Google “helpfully” interprets search terms in a way that often loses sight of the specific query, while AI models generally retain the context and intention of the user’s input, making it easier to reach more relevant results.
I’ve always been a skeptical passenger on the AI bandwagon, and was never completely satisfied with its output. As Dan Sinker noted in a recent blog post, AI is by its nature a “mediocrity machine”, because all it’s really doing is calculating the most statistically likely response to a user’s input.1 With that in mind, it was never likely to replace great artists or innovators, but I could see its potential in automating more boring tasks than we previously could, thanks to its ability to interpret and produce natural language.
AI is often confidently wrong, even when given the simplest requests. If we can't trust it with basics, how can we trust it with more complex tasks?
However, other than the poor quality of its writing (as Paul Graham put it, LLMs write like a kid targeting an essay word count), the other big issue is how often AI is confidently wrong. If it doesn’t understand the context or no data is available, it rarely admits that.2 The internet is full of screenshots of AI models being defiantly incorrect over facts as basic as what year it is.
This unreliability means that even where AI could be useful in automation, it would require constant supervision and review. If I can’t trust it to return a basic fact, how could I possibly trust it to decide whether a customer should be granted a refund, or - gulp - make a change to a production system?
Agentic AI - more than marketing hype
However, in the last year or so, a new development has emerged that has potential to protect against many of the risks inherent in the very nature of AI. Popularised by Andrew Ng in June 2024, the term “agentic AI” refers to AI systems that are capable of handling multiple process steps, rather than just a simple prompt-response model - but it goes a lot further than that.
Agentic AI felt like another marketing buzzword, and to be honest, the current environment in tech likely pushed me in that direction. Beyond the usual sales hyperbole, we’ve also seen incidents of “AI washing”, where companies purport their AI implementations to be much more advanced than they really are. I’ve encountered substantial AI skepticism at some vendor events I’ve attended this year, likely as a result of these tactics.
When agentic AI started cropping up more frequently, I wasn’t convinced. It seemed like a step forward in terms of AI’s capability to integrate with more complex systems, but it wasn’t clear how it would address its underlying reliability problems and make it possible to depend on those systems.
However, I recently encountered OpenAI’s guide to building AI agents, and the diagrams and explanations of agentic AI system design had me sold. The way I see it, agentic AI is less a buzzword for a new type of AI, and more a descriptor for an architecture that could finally give AI the structure and oversight it needs to be reliable enough to be more broadly useful.
Mileage may vary
In the spirit of the aforementioned AI washing, there are likely vendors out there exploiting the newfound popularity of the term "agentic AI" within their marketing materials. Unfortunately, AI implementations are usually typically opaque and it can be difficult to validate what's happening under the hood - so buyer beware, unless you can see the workflows with your own eyes.
New architecture, same problems?
One might expect to encounter the same reliability issues in an agentic AI system that we see in daily use of LLMs. After all, if the model is unreliable, it would be logical that use of that model would be unreliable regardless of underlying structure, and especially if it was handed greater autonomy.
However, guardrails can be put in place to help the system identify improper use or decisions that require human input. What made things click for me was OpenAI’s description of a decentralised system, with multiple agents specialising in their own tasks with stricter rules of engagement.
Where data is passed between specialist agents, each can operate with a narrower scope of accepted inputs and outputs. While no individual agent is more reliable than the underlying AI model, the system as a whole is more likely to identify errors made at previous steps and flag them for review.
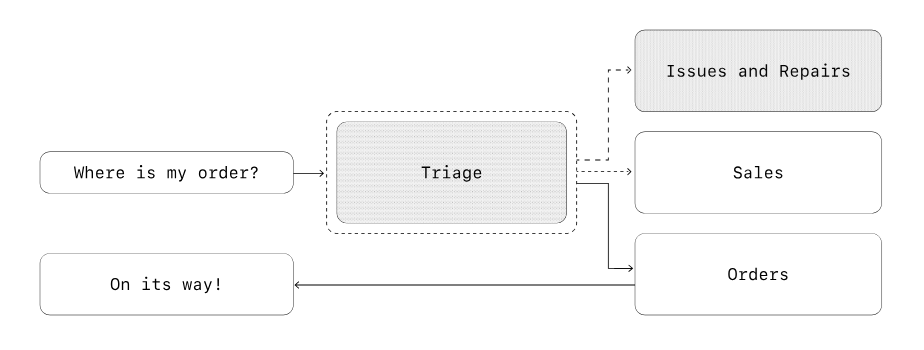
Agent-specific guardrails define what those boundaries are, both for user experience and for security. One element is input and output validation, to identify irrelevant or malicious requests, prompt injection attempts, accidentally exposed personally identifiable information, and so on.
Security remains a concern given the broad and often unpredictable attack surface of autonomous AI agents. OpenAI suggests implementing guardrails “to address the risks you’ve already identified… and layer in additional ones as you uncover new vulnerabilities”, which is a potentially infinite task with a trial-and-error element that is hardly reassuring. I would expect this perpetual battle to develop into a whole new vertical in cyber security.
The second layer of guardrails demonstrated in OpenAI’s document identify high-risk scenarios where an agent is out of its depth and requires human intervention. This takes decisions with significant impact - for example, whether a customer is entitled to a sizeable refund - out of the AI system’s hands and escalates them to receive the human attention they need, while avoiding lumbering workers with review of every mundane request.
The road ahead
Equipped with proper guardrails, agentic AI systems address many of the reservations I have about letting autonomous AI loose in a business context. By confining each agent to a narrow scope, the architecture provides review of each agent’s work and it’s more likely that rogue inputs and hallucinations will be detected and flagged for review and correction. Meanwhile, the AI system is still able to execute most of the work under its own steam.
A lot remains to be seen as agentic AI develops in the coming years. Defining guardrails is a critical component - it will be some time before we can be confident they are effective enough, and they will continue to evolve as new abuse techniques and failures come to light. Furthermore, much depends on individual developers’ implementations, and if recent activity in the sector is anything to go by, validating what vendors mean when they promise “agentic AI” in their sales material will remain a challenge well into the future.
Maybe I’ll eat my words in ten years’ time - that’s part of the fun of the tech space - but despite the hurdles yet to be overcome, the advent of agentic AI feels like a turning point, and perhaps the catalyst needed for AI to operate autonomously and reliably in environments where mistakes matter.
Notes and references
-
Coincidentally, just before I published this post, Apple researchers put out a new paper titled The Illusion of Thinking, which concludes that current AI models do well at pattern matching, but fall apart when more complex reasoning is required to solve a problem.
-
I wrote a little while ago about how the personification of AI models exacerbates this problem, increasing a user’s natural inclination to trust output that if anything they should be more suspicious of.