Backutil development: Building and JOINing SQLite databases in Python
This post is something of a development diary for Backutil - my Python-based utility for backing up files from Windows systems. I published the first version of Backutil (v0.51) at the beginning of 2021, and pushed a small update (v0.52) to fix some minor issues in February.
As of v0.52, the utility still relied on text files full of file hashes to remember what it had backed up, and in-memory Pandas dataframes to compare the files currently on the system to the previous file hashes and work out what to back up. The full process looked something like this:
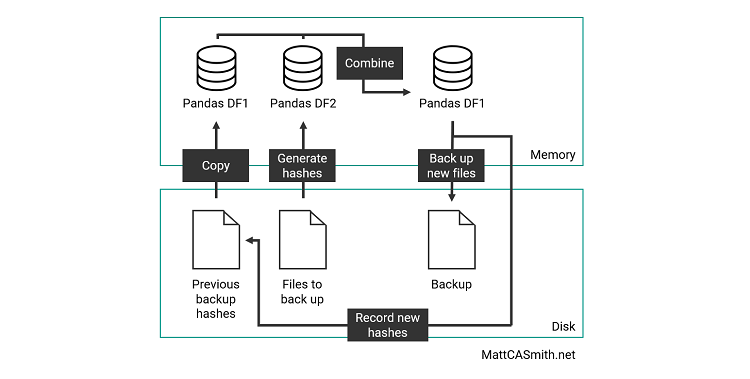
For v0.61, I wanted to streamline this somewhat, and hopefully speed up the process (this will be boosted by a multithreading implementation in a future update). The solution? SQLite - as the name would suggest, a lighter version of SQL that can be used to store databases either in memory or as files via the Python sqlite3 library. This enabled me to use SQL functions like INSERT, DELETE and JOIN to more efficiently manipulate the backup data. The new process looks like this:
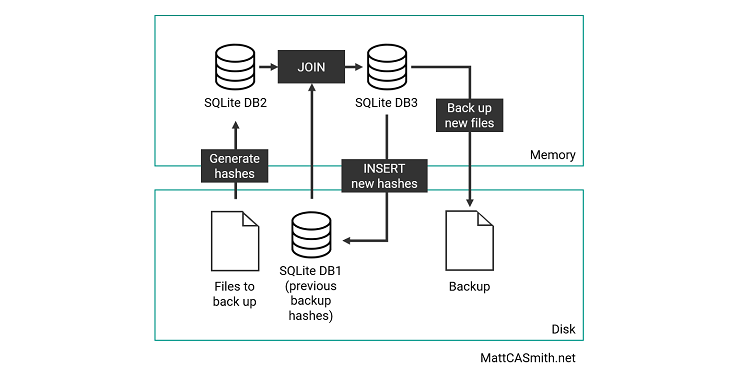
To demonstrate this, I’ll run through a few examples of how SQLite is used in the latest version.
Managing the database connection
Before we can use a SQLite database, we must connect to it. As this would happen several times through the code, I defined a function that takes the config class and action variable. If the action is open, we connect to the database and create the backutil_previous table if it does not already exist.
if action == "open":
config.db_conn = sqlite3.connect(config.db_name)
config.db_cursor = config.db_conn.cursor()
config.db_cursor.execute("CREATE TABLE IF NOT EXISTS backutil_previous(date TEXT, hash TEXT);")If the action supplied to the function is close, we close the connection to the database.
if action == "close":
config.db_conn.close()With this function defined and actions taken according to the contents of the action variable, we can open and close the database using a single line elsewhere in the code.
Getting previous backup dates
In order to work out whether the backups need to be rotated, Backutil previously counted the number of .back text files in its directory. Now, however, we can use SELECT DISTINCT to get a list of unique timestamps of previous backups from the SQLite database stored on disk.
backup_dates=[]
db_dates = config.previous_db_cursor.execute("SELECT DISTINCT date FROM backutil_previous ORDER BY date ASC;")
for date in db_dates:
backup_dates.append(date[0])This code iterates through the returned dates and adds them to a Python list named backup_dates, the length of which is subsequently counted to determine whether there are more backups than required.
Deleting data from old backups
If there are too many backups, the oldest backup must be deleted, along with its entries in the previous backups database. We can take the oldest date from backup_dates and use the DELETE operation. Using question marks in sqlite3 inserts items from the supplied variable - in this case query_data - and is best practice to protect against SQL injection by interpreting strings only as literal values.
if len(backup_dates) > (config.backups_retained - 1) and (config.backups_rotated == "True"):
query_data = (str(backup_dates[0]),)
config.previous_db_cursor.execute("DELETE FROM backutil_previous WHERE date = ?;", query_data)
config.previous_db_conn.commit()Another important note here is that after an operation is executed that would change a SQLite database, it must be committed. If we did not commit our changes to the database, it would not be written to the file on disk. Once the changes are committed, we have deleted the oldest backup hash entries for good.
Checking old backup hashes against current files
Meanwhile, a separate database named backutil_tracker has been built in memory, containing the hashes of all the files that currently reside in the backup directories. To work out which files are new and need to be backed up, we must compare them to the hashes in backutil_previous.
We can use ATTACH to enable cross-database operations, then perform a LEFT JOIN (see my previous post on SQL JOINs for all the details) to combine the data from the two tables based on the file hashes.
query_data = (config.previous_db_name,)
config.tracker_db_cursor.execute("ATTACH ? as backutil_previous", query_data)
results = config.tracker_db_cursor.execute("SELECT backutil_tracker.file, backutil_tracker.hash, backutil_previous.date FROM backutil_tracker LEFT JOIN backutil_previous ON backutil_tracker.hash=backutil_previous.hash;")
for line in results:
if line[2] == None:
config.files_to_back_up.append(line)If a hash in backutil_tracker matches a hash in backutil_previous, the date that file was backed up is copied to the table. Once all hashes have been checked, we know that rows with None in the date column do not exist in previous backups. These are copied to a Python list that will be supplied to the backup loop. This way, only new files are added to the new backup.
Writing backed up files to the database
As Backutil successfully copies files, it appends their rows to the files_backed_up list. Once all files have been safely copied, compressed, and encrypted, we can INSERT the contents of this list into the backutil_previous table, which is stored on disk for future reference.
We open the database connection again, execute the INSERT operation, then commit the changes. The new hashes will be written to the database with the timestamp of the new backup.
manage_previous_db(config, "open")
for backed_up_file in config.files_backed_up:
query_data = (config.backup_time, backed_up_file)
config.previous_db_cursor.execute("INSERT INTO backutil_previous (date, hash) VALUES (?, ?);", query_data)
config.previous_db_conn.commit()
manage_previous_db(config, "close")With our files backed up and the new hashes written to backutil_previous, we can close our database connection. The database will remain on disk until it is called upon during the next backup, at which time Backutil will not copy the same files again because their hashes are now in the database.