Backutil development: Implementing multiprocessing in Python
I’m still hard at work on Backutil, my simple Windows backup utility with automatic rotation features, fitting in little tweaks and improvements around my daily schedule. The latest of these - and perhaps the most impactful in terms of performance - involves the implementation of multiprocessing for several parts of the code, which I thought was significant and interesting enough to warrant a write-up.
Why implement multiprocessing?
By default, Python scripts execute in a single processor thread. This is the equivalent of a road with a single lane of traffic. This is fine for most parts of the code, but consider some of the operations involved in Backutil - specifically the section that generates hashes for all the files in the backup directories (also the bit that copies files, but we’ll stick to one example in this post to keep things simple).

There’s a clear bottleneck in this scenario. That one processor core is being worked hard, tasked with generating all the hashes (yes, there may be other factors at play, like disk read speed, but we’ll ignore that for the purpose of this walkthrough). Even if my computer has six processor cores, we’re only using one. This inefficiency means the script takes longer to run over large batches of files.
But what if we could use multiple cores at the same time? This would be akin to a road with many lanes of traffic - like turn one at the Baku Formula 1 street circuit on a normal day (just more efficient). Let’s try breaking our lists of files into chunks - three, for the sake of argument - and handling them separately.
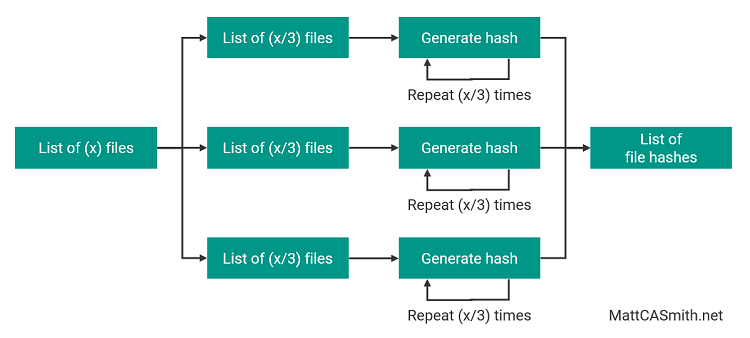
That’s better! Now we’ve split the list into parts and assigned each to its own process, we can use more of the computer’s potential and - in theory, at least - complete the task in a third of the time it would have taken using our previous process. Then we recombine the results for use in the rest of the program.
Writing a function to generate hashes
To spawn separate processes to handle the hash generation, we need to define a function to do the dirty work. Each time we start an additional process, we will invoke this function and supply it with a subset of the data. For the purposes of generating file hashes, that will look like this:
def generate_hashes(procnum, backup_files_thread, return_dict, version):
colorama.init()
return_dict_process = {}
for filename in backup_files_thread:
try:
sha256_hash = hashlib.sha256()
with open(filename,"rb") as f:
for byte_block in iter(lambda: f.read(65535),b""):
sha256_hash.update(byte_block)
hash_output = (sha256_hash.hexdigest())
return_dict_process[filename] = hash_output
except:
msg = "Couldn't generate hash for " + filename
log(msg, "Warning", version)
return_dict[procnum] = return_dict_processI won’t go into detail on the hash generation itself - that’s for a different post - but I will point out some important elements as far as multiprocessing is concerned.
First, take a look at the arguments that generate_hashes takes as input. The variable procnum will let us assign each subprocess an identifier, backup_files_thread will be used to supply the data that the subprocess will work on, and version is just the Backutil version number for logging purposes.
The special dictionary return_dict will combine output from our subprocesses - more on that later. All we need to note now is that the final line of our function adds function output (return_dict_process) as an entry in this dictionary, using the subprocess identifier (procnum) as a key.
Splitting the dataset into chunks
But we can’t simply tell Python, or the multiprocessing library, to take our list of files to generate hashes for and split it between x processes. That would be too easy. We need to do the hard work ourselves and split the data (a list called backup_files, full of file paths) into equal chunks.
split_backup_files = (backup_files[i::config.max_threads] for i in range(config.max_threads))When this line of code has done its thing, we’ll be left with a new list called split_backup_files, within which will be a number of equal lists equal to the config.max_threads variable, which the user should configure to be equal to the number of processor cores they want Backutil to use.
Assigning each chunk to a subprocess
We’re nearly ready to get our subprocesses up and running, but before we do so there’s some housekeeping to take care of to keep track of processes and their output.
In the first few lines of setup, process_container will be used to track all the processes we create, while manager - and specifically manager.dict() as return_dict - will provide a kind of magic dictionary that will take the output from each process (we saw the line in the function for this earlier). The x value will track process IDs as we create them, iterating by one each time.
process_container = []
manager = multiprocessing.Manager()
return_dict = manager.dict()
x = 1
for backup_files_thread in split_backup_files:
name = "Process-" + str(x)
process = multiprocessing.Process(target=generate_hashes, name=name, args=(x, backup_files_thread, return_dict, version,))
process_container.append(process)
process.start()
x += 1
for process in process_container:
process.join()Now for the real action. We iterate over split_backup_files (you’ll remember the number of lists inside is equal to the number of threads) and for each item we use multiprocessing.Process to create Process X. The target is our function, the name comes from the variable we just created, and we supply all our function’s arguments in args. The process is appended to process_container for safekeeping, and with process.start() we’re officially multiprocessing!
One more important action for each process in the container here is process.join(). This ensures that our parent process waits for each child process to finish before proceeding, ensuring we don’t start trying to use our hashes before they’ve all been generated and returned.
Checking subprocess exit state
Time to build in a bit of resilience. The generate_hashes function won’t fail if a single hash generation fails, but in the unlikely event that one of our subprocesses fails, we don’t want to proceed and complete a partial backup without the user knowing. Instead, we’ll check they succeed and interrupt Backutil if not.
for process in process_container:
if process.exitcode == 0:
continue
else:
log("Hash generation thread failed.", "Failure", version)
sys.exit()To achieve this, we iterate over the processes in process_container and check the value of process.exitcode for each. If it’s 0 (success), and if it’s not then we log the error before calling sys.exit() to end the program. Backutil will automatically clean up any temporary files on its way out.
Recombining the dataset
So we split our data, we processed it, and each subprocess has returned its output dictionary as an entry in the dictionary return_dict with the process number as the key. As the final step, we want to recombine the returned hashes so they can be used elsewhere in the program.
combined_dict = {}
for dictionary in return_dict.values():
for key, value in dictionary.items():
combined_dict[key] = valueThis is simple enough: We establish the dictionary combined_dict for our output and begin to iterate over the values in return_dict. Each key-value pair in each process’s returned dictionary is appended to combined_dict. After all the entries have been processed, we’ve recombined our data!
Multiprocessing in action
One of the nice (and convenient) things about multiprocessing is that - unlike most Python structures and implementations - we can see it in action directly in the operating system, rather than using variable explorers or debug print statements. On Windows, we can simply check the Task Manager.
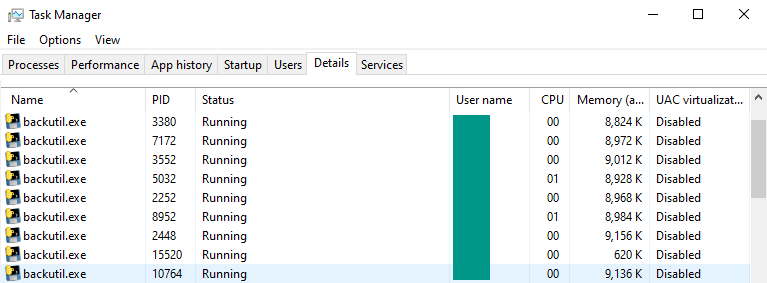
In the Details tab, we can see all of our currently running processes. By sorting them by name and finding all instances of backutil.exe, we can see a number of processes equal to the config.max_threads variable we saw earlier, plus the parent process - so we know multiprocessing is working properly.
Multiprocessing on Windows with PyInstaller
I do have one more small note if you’re building a Python program for Windows using multiprocessing and you’re planning on converting it to an .exe file using PyInstaller. In this case, you could do everything described above perfectly, and when you run your executable you’ll receive an error.
Luckily, you need only one line of code to fix this.
if __name__ == "__main__":
multiprocessing.freeze_support()You must put multiprocessing.freeze_support() at the start of this section of your code, but if you do this and recompile your executable with PyInstaller then everything should work again.