Grabbing domains and URLs from tcpdump data using Python
There’s a lot more to most websites than meets the eye these days, and I thought an interesting Python project to take on at the start of my Christmas break would be to uncover the extra requests hidden below the surface with some help from tcpdump.
The challenge? Tcpdump’s output is a huge list of the packets it captures, each one loaded with so much information that scanning the raw output for the domains and URLs that give away sites’ activity is near impossible. Luckily, Python has a few tricks up its sleeve that can help to filter out the data we need in a more readable format.
Setup and running tcpdump
As usual, the first step is to get the basics set up. This means importing the os module and using it to run the tcpdump command that will give us some data to play with.
import os
os.system(‘sudo tcpdump > tcpdump_data’)
I’ve gone for the vanilla version, but you could jazz this up by specifying ports or other network interfaces if needed. Everything that’s captured will be stored in a file called tcpdump_data, ready for us to start picking out the interesting bits.
Loading the data and defining keywords
Now the tcpdump process is complete and the data exists, it’s time to load it with Python (the “r” allows us to read the file) and define the keywords we’re looking for.
tcpdump_data = open(“tcpdump_data”, “r”)
keyword1 = ‘HTTP: GET’
keyword2 = ‘AAA?’
I’m interested in seeing which websites have been browsed, so I want to pick out two key bits of data: DNS requests (preceded by “AAA?”), which will show the domains visited, and HTTP GET requests (preceded by “HTTP: GET”), which will show the individual directories and pages browsed, albeit only for sites that use HTTP and not HTTPS.
Defining some pretty colours
Although you could do fancier things with this kind of script, in my example both of these pieces of data will be displayed in one feed, so it’d be nice to show them in different colours to make them a bit easier to pick out. I’ll use purple and yellow.
class colours:
PURPLE = ‘\033[95m’
YELLOW = ‘\033[93m’
I had to do a bit of Googling to work out how to do this. As usual, it was Stack Overflow that came up with solution – in this case one that uses a simple class to define colours.
Parsing the tcpdump data
Now it’s time to do the heavy work – parsing the tcpdump data we produced and opened earlier and picking out the domains and GET request paths that we come after our keywords.
for line in tcpdump_data:
if keyword1 in line:
data = line.split(“GET “, 1)[1]
print colours.PURPLE + data,
if keyword2 in line:
data = line.split(“AAA? “, 1)[1]
print colours.YELLOW + data,
Here we iterate through the data line by line, looking for occurrences of “HTTP: GET” and “AAA?”. If one of these keywords exists in a line, the words after it (i.e. the domains and URL paths) will be printed to the terminal in some nice colours.
Output
The result is a list that gives us an interesting look at the requests that go on in the background when we visit websites – take the BBC News site, for example:
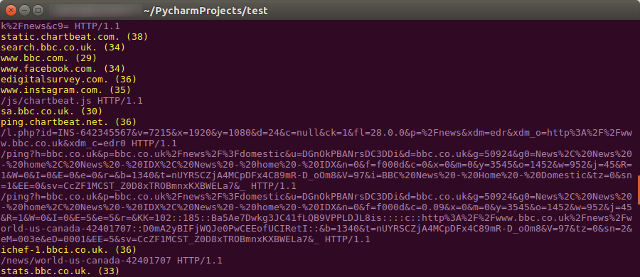
There’s plenty more potential here, too. These data sets could be written to separate files, for example, or stored in a way that more clearly shows the association between each entry. But my main objective was to see if I could scrape the relevant data and make it easier to read domains and URLs from tcpdump, and I’m happy with the result.
A note: I’m only just delving into the world of Python, and these posts are as much to get things straight in my own head as they are to show them to others. If anything looks wrong, or there’s a more efficient way of doing something, please let me know!
Photo © Chris Dlugosz (CC BY 2.0). Cropped.