Checking DNS requests against a domain blacklist in Python

A while ago I wrote a post about using Python to parse tcpdump output for domains and URLs. Recently, I started to wonder if I could take that a step further. What if the DNS requests I saw could be checked against a blacklist in real time? And what if the output was presented in a more useful format? Here’s how I got these new features working.
Setting everything up
As usual, we have some Python modules to import before we get started, and we’re also going to define a main() function and a couple of useful variables.
from __future__ import print_function
import time
import os
import subprocess as sub
def main():
clear = "\b"*300
keyword = 'AAA?'The top print_function line will allow us to use Python 3-style print statements, time will let us fetch the date and time, os is necessary to run tcpdump, and subprocess makes it possible to do this in the background and analyse the results as they are generated.
Within our main() function, the clear variable contains a load of backspaces and will be used to update text on the screen to show progress. The keyword variable will be used to locate AAA DNS requests in the tcpdump output so we can find some domains.
Getting domains from tcpdump
It’s time to get tcpdump running! The top line uses the subprocess module to run tcpdump in the background and pipe the output to our Python script so we can analyse it.
tcpdump = sub.Popen(('sudo', 'tcpdump', '-l'), stdout=sub.PIPE)
for line in iter(tcpdump.stdout.readline, b''):
if keyword in line:
current_domain = line.split("AAA? ", 1)[1]
current_domain = current_domain[:-7]The next section begins iterating over this data line by line (notice the readline attribute). If our keyword, “AAA?”, is in the line, the domain that comes after that text will be pulled into the current_domain variable, after which seven characters of extra data that comes afterwards is filtered out. After this, we’re left with a nice string like “google.com”.
Checking domains against the blacklist
Something to note here: You’ll likely realise that this section of code refers to a blacklist variable that does not yet exist. It’s a Python list containing known malicious domains – we’ll see how it’s set up (and where all that lovely data comes from) later.
blacklist_detector = 0
for domain in blacklist:
if domain in current_domain:
current_blackliststatus = "Y"
blacklist_detector = 1
else:
pass
if blacklist_detector == 0:
current_blackliststatus = "N"
else:
pass<So what’s happening here? The script takes each domain in the blacklist list and compares it to the current domain. If the blacklist entry is present, this is flagged in a variable and blacklist_detector is set to 1. If no blacklist entries match, blacklist_detector remains at 0 and the last if statement adds this information to current_blackliststatus.
Adding log information and saving
There’s a little more information we need to turn this data into a useful log entry, so this section grabs the current date and time and combines it with the current domain and the blacklist_status into a single event variable, with each field separated by commas and a return at the end so we can send the output to a CSV file.
current_date = time.strftime("%d/%m/%Y")
current_time = time.strftime("%H:%M:%S")
current_log = current_date + "," + current_time + "," + current_domain + "," + current_blackliststatus + "\n"
database_file.write(current_log)
print (clear, current_domain, " added", end="", sep="")
else:
passAnd that’s just what we do when the script appends the log event to the database_file (another variable we’ll set up in a moment). So we can be sure the script is working, it also prints data to the screen in the format “google.com added”. By removing the new line from the end attribute and printing the backspaces in our clear variable first, we can write over existing data on the screen on the same line rather than printing a huge list.
Finally, we close up the line iteration for loop from the first section by including an else statement. If the line doesn’t contain our keyword, we’ll pass and move onto the next one.
File and blacklist initialisation
Here, outside of the main() function, we set up those variables we saw earlier. This is the first code that will run and handles some critical setup that allows the main function to work.
database_file = open("weblog.csv", "a")
blacklist_file = open("blacklist.txt", "r")
blacklist = []
for line in blacklist_file:
line = line[:-1]
blacklist.append(line)
blacklist = blacklist[:-1]
main()The top section opens our log CSV file in append mode, to let us add new lines to it. Then we open the blacklist, which is a simple text file with one domain per line. There are a ton of ways you could gather data on malicious domains, but I found the resources at the SANS Internet Storm Center to be a useful place to start.
Once we have our blacklist, the next part sets up a Python list and adds each malicious domain as an entry (minus the new line that comes afterwards). Now we’re set up and ready to go, we call our main() function and get to work on our tcpdump data.
Output
So what happens when we put all this together? To demonstrate, I’ve cleared my weblog file and have added a single domain – google.com – to my blacklist. Now I’m going to run the script, browse the internet, and see what happens.
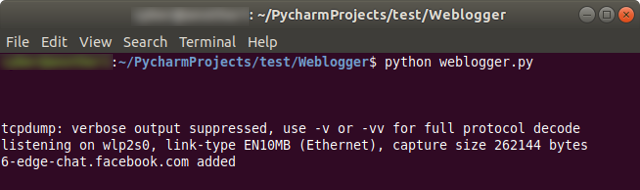
This is what we see while the script is running – tcpdump’s verbose output is suppressed, but the bottom line updates to show domains that are added to our log file. When we terminate the script, we can open weblog.csv to see every DNS request that was made.
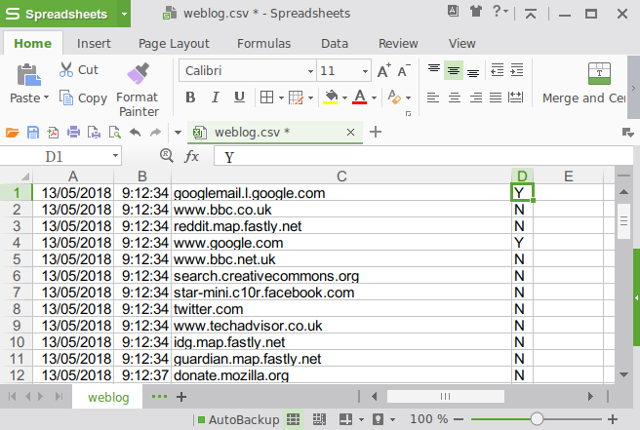
Here’s an excerpt from my own random browsing, and look – the script has flagged two visits to domains containing “google.com” that we might want to look into. Had I been running the script for longer and generated more data, I’d be able to filter by column D to more easily see whether any blacklisted malicious domains were accessed.
The next step for this script? Once I have more than one computer to play with, I’d like to try running a tcpdump logger agent on one and sending the extracted domains across the network to be stored in a central log on the other. Watch this space.
+A note: I’m only just delving into the world of Python, and these posts are as much to get things straight in my own head as they are to show them to others. If anything looks wrong, or there’s a more efficient way of doing something, please let me know!_